Алгоритм вокодера каждой пульсовой волны
06.09.2017
Современные низкоскоростные речевые кодеки обеспечивают удовлетворительное качество передачи сигнала до скоростей примерно 600 бит/сек. Высокое качество речи получается при скоростях более 1200 бит/сек, скорости 200 и менее практически не используются, т.к. разборчивость стремительно падает после значений около 300 бит/сек.
В целом, это великолепный результат, обусловленный тем, что разработка речевых кодеров/декодеров продолжалась длительное время и велась лучшими специалистами (засекречивающая аппаратура связи была остро необходима всем государствам периода холодной войны, а они, в свою очередь, могли привлечь к работе ведущих ученых и инженеров).
Высокая эффективность сжатия речевого сигнала с помощью современных кодеков обусловлена, в основном, тремя методами:
- Эффективным вокодером, который минимизирует количество параметров, необходимых для обеспечения приемлемой разборчивости речи.
- Векторным квантованием, выполняющим функции кластерного метода сжатия.
- Оптимальным линейным предсказанием, позволяющим передавать только невязку между предсказанным и реальным значением передаваемого параметра.
В настоящее время, вероятно, нецелесообразно пытаться разрабатывать еще более низкоскоростные кодеки, т.к. цена ошибки передачи любого бита (в каналах с ошибками) растет пропорционально коэффициенту сжатия, а использование корректирующих кодов с соответствующим увеличением битрейта становится бессмысленным при достижении предельно малых скоростей передачи данных. Следовательно, можно считать, что в области кодирования речи достигнут некоторый практический предел скорости передачи цифровых данных, и он составляет (при приемлемой разборчивости) 700-600 бит в секунду. Например, Kodek2 обеспечивает: David_700C_kodek2.wav
В некоторых разработках заявлено высокое качество даже при скорости 300 бит/сек, но описание алгоритмов и открытых программных модулей таких кодеков автору не встречались.
Тем не менее, задача проектирования сверхнизкоскоростного кодека не оставляет в покое энтузиастов. Результатом, обычно, является только огромный труд и потерянное время. С учетом такого негативного опыта допустимо предположить, что в пределах «столбовой дороги», проложенной выдающимися специалистами, ничего принципиального не будет, а возможны только небольшие косметические улучшения. Поэтому необходимо сойти с этой дороги и отказаться от применения важнейших аксиоматических алгоритмов – векторного квантования и оптимального линейного предсказания. Вокодер, понятно, заменить невозможно, но модифицировать допустимо.
Мысленно вернемся на несколько десятилетий назад и вновь критически оценим модель голосового аппарата человека.
Известно, что пульсовая волна, обусловленная смыканием голосовых связок, должна быть выделена с минимальной погрешностью. Существующие же алгоритмы выделения основного тона речи «не делают культа» из этого требования – ими допускается смещение центра окна данных спектроанализатора относительно максимального выброса в пульсовой волне.
Однако можно предполагать, что система слабосвязанных осцилляторов (а именно к ней, по моему мнению, сводима модель голосового тракта) под действием импульсной «подкачки» энергии после смыкания голосовых связок неизбежно обеспечит появление глобального экстремума на ограниченном временном интервале. Тогда обнаружение пульсовой волны становится тривиальной задачей (если не искать максимум вместо экстремума).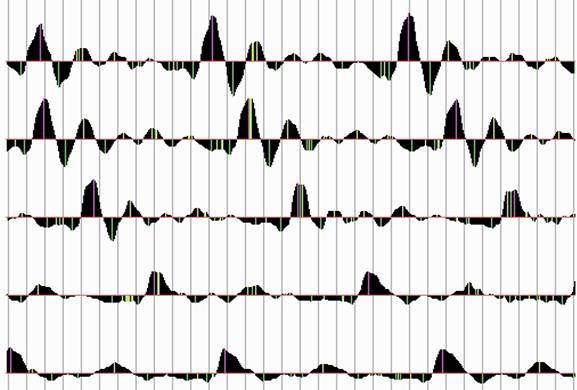
Рис.1 Автоматическое обнаружение экстремумов – сиреневым цветом показаны глобальные на интервале пульсовой волны экстремумы. Сетка – 1мсек.
Но выбор реализации, на котором искомый экстремум является глобальным, представляет собой серьезную проблему. Она наилучшим образом решается только с помощью предсказания длины временного интервала, в котором следует искать экстремумы. При этом в качестве опорных данных используется усредненное значение периодов предыдущих пульсовых волн. 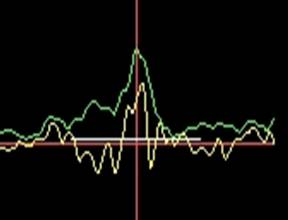
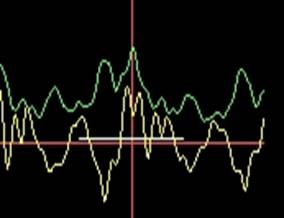
Рис.2 Обнаружение экстремумов. Желтым цветом выделен исходный сигнал, зеленым – сигнал после двуфазного выпрямления и ограничения полосы, белым – предсказанный интервал, в котором ведется поиск.
Если система обнаружения экстремумов работает стабильно и надежно как для вокализованных звуков, так и для шипящих и свистящих фонем (глобальный на заданном интервале экстремум находится всегда), то расположение центра окна данных для спектрального оценивания обеспечивается наилучшим образом. Естественно, в таком случае анализ процесса, вызванного каждым импульсом смыкания связок, происходит максимально единообразно, а спектры каждой пульсовой волны точно «привязаны» к ней.
Кроме того, автор предполагает, что существующий выбор малого количества частотных полос и использование БПФ для спектрального оценивания в современных вокодерах представляют собой широко распространенную досадную ошибку. Как заметил Марпл младший: «... практика применения методов спектрального оценивания с использованием конечных наборов данных не составляет собой некую точную науку: она в значительной мере основывается на результатах экспериментов и обычно требует тех или иных конкретных компромиссов».
Итак, выберем достаточное количество частотных полос (64) и будем вычислять энергетический спектр реализации методом ДПФ, используя логарифмическую шкалу по частотной оси. Будем применять окно Тьюки и введем соответствующие спектру речи предыскажения АЧХ для отбеливания результатов. Используем спектр каждой пульсовой волны для заполнения спектрограммы процесса. Подав данные спектрограммы на блок синтезатора с соответствующей обратной коррекцией АЧХ, мы сможем убедиться, что речевой сигнал (за исключением фазочастотных соотношений) восстановлен, и требуемая разборчивость обеспечена полностью (примерно так работают вокодеры в эстрадных синтезаторах, а качество их звучания выше всяких похвал).
Далее необходимо сжимать получившийся поток данных, причем сжимать с учетом особенностей речевого аппарата. Известно, что для передачи речевого сигнала достаточно иметь информацию о текущей частоте пульса и двух частотах основных резонаторов – т.е. доминантной и субдоминантной спектральных составляющих. Если же мы будем обеспечивать передачу данных для каждой пульсовой волны, а не для фрагмента речевого сигнала, то достаточно передать амплитуду и частоту доминантной компоненты и соответственно субдоминантной. Учитываем, что разделение сигнала на 64 частотных полосы избыточно и необходимо только для эффективного отбеливания и последующей селекции компонент. Тогда допустимо сократить количество полос до 16, т.е. объединять компоненты в группы 4:1. Проведенными экспериментами (автор от них чуть не издох) подтверждено, что амплитудные значения в огрубленных (до 16-ти) частотных полосах должны соответствовать максимумам (а не средним значениям(!), это принципиальная ошибка классических вокодеров) в соответствующих четверках. Только в этом случае обеспечивается разборчивый и не «мутный» синтезированный сигнал.
Теперь обратим внимание, что информация о частотах (для каждой пульсовой волны имеются два тона – т.е. две «ноты») совпадает с понятием аккорда, которое уже много столетий используется в музыкальной (нотной) грамоте.
Рис.3 Редуцированная спектрограмма для 16-ти частотных полос и выделения только двух спектральных компонент (вверху). Сформированные из спектрограммы методом дельта модуляции «аккорды» (внизу). Единица измерения по оси абсцисс – пульсовая волна.
Кроме того, мы вправе предположить, что значения частот не независимы друг от друга, а составляют комбинации, причем одни из них встречаются чаще, а другие реже. Следовательно, в речевом сигнале будут аккорды, встречающиеся часто, и аккорды достаточно редкие. Тогда, получив функцию распределения аккордов, мы сможем выполнить неискажающее сжатие, более эффективное, чем эффект от использования векторного квантования с его искажающим сжатием и пока никем не разрешенной основной задачей кластерного анализа. Разумеется, закон распределения должен существенно отличаться от равномерного – и здесь возможна лишь экспериментальная проверка.
Рис.4 Функция распределения аккордов. Стрелкой показан центр масс, и он соответствует 4-м битам.
Теперь при наличии информации о двух частотах (4+4 бита или один аккорд) необходимо решить задачу о способе кодирования амплитуды передаваемых спектральных компонент. И именно здесь допустимо искажающее сжатие, т.к. в амплитудной области чувствительность слуха подчиняется логарифмическому закону и «цена погрешности» кодирования будет мала вследствие особенностей восприятия речевого сигнала.
Примем простое правило: если аккорд обновился, и/или его необходимо передать, то увеличиваем амплитуду сигналов на 6дБ, если же передачи для данной пульсовой волны нет (передается аккорд номер 0), то понижаем амплитуду на 3дБ. В передатчике, естественно, для получения опорной амплитуды моделируем восстановление сигнала (идентичное восстановлению в приемнике). Для дополнительного сжатия допустимо запрещать обновление аккорда на 2-3 пульсовые волны т.к. в речевом сигнале одиночные пульсовые волны не используются.
В результате имеем редуцированный вариант дельта модуляции с неизбежными бросками амплитуды в разных пульсовых волнах. Но наш слух усредняет эти значения, и речь воспринимается вполне удовлетворительно.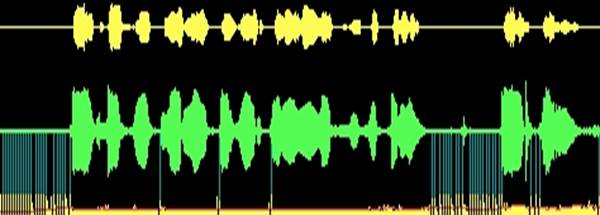
Рис.5 Исходный речевой сигнал (выделен зеленым цветом), вверху желтым цветом показан сигнал после синтезатора - хорошо видны искажения огибающей. Внизу выделен период основного тона, красным – принятое решение на поиск следующего экстремума. Вертикальные отметки – периоды, когда интервал превышает 20 мсек, и волна не обнаруживается.
Оценим выходной битрейт такого вокодера для частоты основного тона высокого мужского голоса 200Гц. Без учета периодов малого уровня сигнала (пауз между словами) считаем, что для потребных в среднем 4 бита на одну волну необходимо 800 бит/сек. (Для передачи номера аккорда в среднем необходимо 4 бита, хотя аккордов 256, см. функцию распределения). Но с учетом «нулевых», т.е. не нуждающихся в передаче аккордов, и запрета на обновление аккорда ранее, чем через 3 волны, потребный поток снижается до 200 бит/сек и менее (зависит от особенностей речи). Правильнее будет считать в битах на пульсовую волну, т.е. примерно 1 бит/волна.
Кроме того, цифровая последовательность вокодера несимметрична: количество нулей в разы(!) превышает количество единиц. Это дает возможность использовать простые методы сжатия типа префиксного кодирования, и места для коррекции частоты основного тона методом дельта модуляции также остается достаточно. Экспериментальные данные показывают потребный битрейт 140-190 бит/сек для мужского голоса и 180-260 для женского. Ни в каком случае не следует понимать эти данные как нижний предел, работа по компрессии данных не закончена и продолжена не будет. Впрочем, упаковка данных и организация фреймов и не рассматривались как задача, которую нужно решить. Причина в том, что проектирование новых вокодеров изначально нецелесообразно и обречено на ненужность в современном инженерном обеспечении новых систем связи.
Продемонстрируем работу вокодера каждой пульсовой волны с выходным потоком 200 бит/сек, начнем с опорного сигнала, т.е. используем МЕLP, настроенный на такое же сжатие - настройку этого кодека для исключения предвзятости автора производил специалист, занимающийся разработкой цифровых радиостанций (обсуждение есть на сайте electronix.ru): 200bivoiceMelp.wav.
Очевидно, что качество при такой скорости неудовлетворительно. Увеличим скорость до 400 бит/сек, и именно этот сигнал будем считать базой для сравнения: 400bivoiceMelp.wav.
Теперь прослушаем тот же фрагмент, обработанный предлагаемым вокодером на скорости 200 (193, если быть точным): my_bivoice200.WAV.
Автор приносит извинения за повышенный уровень шума при синтезе, но объем работы превысил мыслимые пределы, и было не до таких мелочей. Обратим, однако, внимание, что диктор сделала ошибку в чтении и сказала «парового» вместо «правого». И это явно слышно.
Теперь с помощью методики и тестовых фраз ГОСТ проверим работу в случае большого количества свистящих и шипящих звуков – это наиболее сложный вариант для заявляемого вокодера. Скорость та же: my_female200.WAV.
В принципе, качество звучания не проигрывает в сравнении с 800 бит/сек от MELP: female_MELP_0.8kHz.wav.
Итог – такое качество звучания, по моему мнению, пригодно только для служебной связи. Если же во время синтеза иллюстрировать аккорды реализациями во временной области, то можно получить очень хорошее качество звука. Но смена диктора и даже изменение его эмоционального состояния превращают синтезированный сигнал в неудобоваримую кашу. Эту задачу пока никому решить не удалось, мои эксперименты тоже не привели к успеху.
В целом, можно сформулировать единственный вывод: «столбовая дорога», по которой в свое время пошли разработчики речевых кодеков, не является единственной. Что, безусловно, интересно в историческом плане.
Категории:
- Войдите, чтобы оставлять комментарии
|
|
|