The vocoder algorithm for each pulse wave
09/06/2017
Modern low-speed speech codecs provide the satisfactory quality of signal transmission up to the speed of about 600 bps. High speech quality is obtained at the speed of more than 1200 bps, speeds of 200 and less are practically not used, because the intelligibility rapidly falls after the values of about 300 bps.
In general, this is an excellent result due to the fact that the development of speech codecs/decoders continued for a long time and was conducted by the best specialists (the equipment for secure communication was urgently required in all countries during the Cold War period, and they, in their turn, could attract leading scientists and engineers).
High efficiency of the speech signal compression done with the help of modern codecs is mainly resulting from three methods:
- The effective vocoder, which minimizes the number of parameters necessary for the provision of acceptable speech intelligibility.
- Vector quantization, which performs the functions of the cluster compression method.
- Optimal linear prediction that permits only the discrepancy between the predicted and real value of the transmitted parameter to be transmitted.
At present, it is probably inadvisable to try to develop even lower-speed codecs, because the price of the transmission error of any bit (in channels with errors) increases in proportion to the compression ratio, and the use of the corrective codes with a corresponding increase in bitrate becomes meaningless when extremely low data transmission rates are reached. Therefore, it can be assumed that some practical limit for digital data transmission rate in speech encoding area is reached, and (at acceptable intelligibility) it comes up to 700-600 bits per second. For example, Kodek2 provides: David_700C_kodek2.wav
Some designs claim high quality even at a speed of 300 bps, but the author has not come across the description of algorithms and open software modules of such codecs.
Nevertheless, the task of ultra-low-speed codec design does not leave enthusiasts at ease. The result, usually, turns out to be only a huge amount of work and wasted time. Taking into account such negative experience, it is permissible to assume that there will be nothing fundamental on the "high road" laid by outstanding specialists, and only small cosmetic improvements are possible. Therefore, it is necessary to get off this road and abandon the use of the most important axiomatic algorithms - vector quantization and optimal linear prediction Vocoder, of course, can not be replaced, but it is possible to modify it.
Mentally we will return some decades back and once again critically estimate the model of the human vocal apparatus.
It is known that the pulse wave, caused by the vocal fold closure, should be extracted with a minimum error. The existing algorithms of the basic pitch extraction "do not worship" this requirement - they allow the shift of the center of the spectrum analyzer data window with respect to the maximum pulse wave overshoot.
However, it can be assumed that the system of loosely coupled oscillators (in my opinion, namely to it the vocal tract model is brought down) under the action of impulsive energy "swapping" with the vocal folds being closed will inevitably ensure the appearance of global extremum in a limited time interval. Then, the detection of the pulse wave becomes a trivial task (if the maximum is not sought instead of an extremum).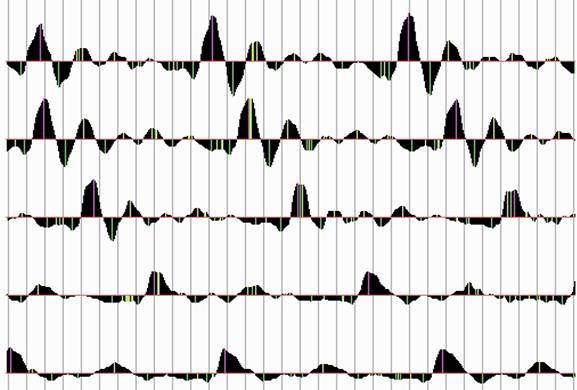
Fig.1 Automatic detection of extrema - the lilac color shows the global extrema on the interval of the pulse wave. The grid is 1 msec.
But the choice of the implementation, on which the desired extremum is global, presents a serious problem. It is best solved only by predicting the length of the time interval in which extrema should be sought. In this case, the averaged value of the periods of the previous pulse waves is used as the reference data. 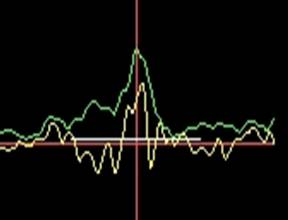
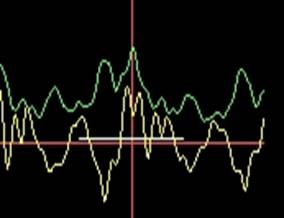
Fig.2 Detection of extrema. The initial signal is highlighted in yellow, the signal after the two-phase rectification and band limitation is in green, white - the predicted interval in which the search is conducted.
If the extrema detection system works consistently and reliably for both voiced sounds and for sibilant phonemes (the global extremum in the given interval is always found), then the location of the center of data window for spectral estimation is provided in the best way. Naturally, in this case, the analysis of the process caused by each impulse of folds closure occurs in the most standard manner, and the spectra of each pulse wave are "tied" exactly to it.
In addition, the author suggests that the existing selection of a small number of frequency bands and the use of FFT for spectral estimation in modern vocoders present a widespread unfortunate mistake. As Marple Jr. remarked: "... the practice of spectral estimation methods application using finite sets of data does not constitute some science: it is based largely on the results of experiments and usually requires certain specific compromises."
So, let us select a sufficient number of frequency bands (64) and calculate the implementation energy spectrum with DFT method using a logarithmic scale along the frequency axis. We will use the Tukey window and introduce the amplitude frequency response predistortions corresponding to the speech spectrum for "legalizing" the results . We use the spectrum of each pulse wave to fill the spectrogram of the process. Directing the spectrogram data to the synthesizer unit with the appropriate deemphasis of the amplitude frequency response, we will be able to verify that the speech signal (with the exception of the phase-frequency relationship) is restored, and the required intelligibility is completely ensured (this is how vocoders work in pop synthesizers, and the quality of their sound is beyond praise).
Next, it is necessary to compress the resulting data stream, and to compress, taking into account the characteristics of the vocal apparatus. It is known that for the transmission of a speech signal it is enough to have the information about the current pulse rate and two frequencies of the main resonators - i.e. dominant and subdominant spectral components. If we provide the data transmission for each pulse wave, and not for a fragment of the speech signal, it is sufficient to transmit the amplitude and frequency of the dominant component and, accordingly, the subdominant. We take into account that splitting a signal into 64 frequency bands is redundant and necessary only for the effective "legalizing" and subsequent selection of components. Then, it is permissible to reduce the number of bands down to 16, i.e. combine the components into 4:1 groups. The conducted experiments (the author nearly died from them) confirmed that the amplitude values in the coarsened (up to 16) frequency bands should correspond to the maxima (and not to the average values (!), this is the fundamental error of classical vocoders) in the corresponding fours. Only in this case a legible and not "blurred" synthesized signal is provided.
Now let us note that the information about frequencies (for each pulse wave there are two tones - i.e. two "notes") coincides with the concept of a chord, which has been used for many centuries in musical literacy.
Fig.3 Reduced spectrogram for 16 frequency bands and the separation of only two spectral components (top). "Chords" formed from the spectrogram by delta modulation method (bottom). The unit of measurement along the axis of abscissa is the pulse wave.
In addition, we have the right to assume that the values of the frequencies are not independent from each other, but make up combinations, with some of them occurring more often and others less frequently. Hence, there will be chords in the speech signal that occur frequently, and chords which are quite rare. Then, having received the chord distribution function, we can perform non-distorting compression, more effective than the effect of vector quantization use with its distorting compression and for the time being not solved main task of cluster analysis. Of course, the distribution law must differ substantially from the uniform, and here only an experimental verification is possible.
Fig.4 Chord distribution function. The arrow shows the mass center, and it corresponds to 4 bits.
Now, if the information about two frequencies (4+4 bits or one chord) is available, it is necessary to solve the problem of the method of the amplitude encoding of the transmitted spectral components. And it is here that the distorting compression is permissible, because in the amplitude range the sensitivity of the hearing is subject to a logarithmic law and the "error price" of the coding will be small due to the peculiarities of the perception of the speech signal.
Let us take a simple rule: if the chord is updated and/or it needs to be transmitted, then we increase the amplitude of the signals by 6dB, if there is no transmission for this pulse wave (0 chord number is transmitted), then we lower the amplitude by 3dB. In the transmitter, of course, in order to obtain the reference amplitude, we model the signal restoration (identical to the restoration in the receiver). For additional compression it is permissible to forbid the chord update by 2-3 pulse waves as single pulse waves are not used in the speech signal.
As a result, we have a reduced version of delta modulation with inevitable amplitude jumps in different pulse waves. But our hearing averages these values, and the speech is perceived quite satisfactorily.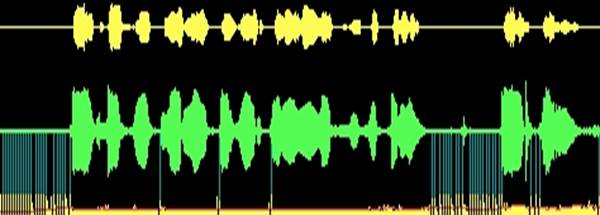
Fig.5 The initial speech signal (highlighted in green), the yellow signal at the top shows the signal after the synthesizer - the distortions of the envelope are clearly visible. At the bottom, the pitch period is highlighted, red is the decision taken to find the next extremum. Vertical marks are periods when the interval exceeds 20 msec and the wave is not being detected.
Let us estimate the output bitrate of such a vocoder for the pitch frequency of the high-pitched male voice of 200Hz. Without taking into account the periods of a small signal level (pauses between words), we assume that for required on average 4 bits per one wave, 800 bps are needed. (To transfer the chord number, on average, 4 bits are required, although there are 256 chords, see the distribution function). But taking into account "zero" chords, i.e. chords that do not need to be transferred, and the ban on chord update earlier than in 3 waves, the required stream is reduced down to 200 bps and less (depending on speech peculiarities). It will be more correct to count in bits for a pulse wave, i.e. approximately 1 bit/wave.
In addition, the vocoder digital sequence is asymmetric: the number of zeros exceeds the number of unities by far (!). This makes it possible to use simple compression methods of the prefix encoding type, and there is also enough space for the pitch frequency correction using delta modulation method. The experimental data show the required bitrate of 140-190 bps for the male voice and 180-260 for the female voice. In no case one should understand this data as a lower limit, the work on data compression is not finished and will not be continued. However, the data packing and the organization of frames were not considered as a task to be solved. The reason is that the design of new vocoders is initially inexpedient and doomed to uselessness in the modern engineering support of new communication systems.
Let us demonstrate the operation of the vocoder of each pulse wave with an output stream of 200 bps, let us start with the reference signal, i.e. we use MELP, configured for the same compression - the tuning of this codec, to exclude the bias of the author, was made by the specialist engaged in the development of digital radio stations (the discussion is available on the website electronix.ru): 200bivoiceMelp.wav.
Obviously, the quality at this speed is unsatisfactory. We will increase the speed up to 400 bps, and this signal will be considered as the basis for comparison: 400bivoiceMelp.wav.
Now let us listen to the same fragment processed by the proposed vocoder at a speed of 200 (193, to be precise): my_bivoice200.WAV.
The author apologizes for the increased noise level in the synthesis, but the amount of work exceeded imaginable limits, and there was no time for such trifles. However, let us pay attention to the fact, that the announcer made a mistake in reading and said "night" instead of "right". And it's clearly audible.
Now with the help of GOST methodology and test phrases we will check the work in the case of large number of sibilant sounds - this is the most difficult option for the claimed vocoder. The speed is the same: my_female200.WAV.
In principle, the sound quality does not compare poorly with 800 bps of MELP: female_MELP_0.8kHz.wav.
The result - this sound quality, in my opinion, is suitable only for the service communication. If during the synthesis one illustrates the chords with realizations in the time domain, one can get a very good sound quality. But the change of the announcer and even the change of the emotional state turns the synthesized signal into an indigestible porridge. This task has not yet been solved by anyone, my experiments have not led to a success either.
In general, we can formulate the single conclusion: "the highway", which the developers of speech codecs followed some time ago, is not the only one. It is, of course, interesting in historical terms.
Category:
- Log in to post comments
|
|
|